Introduction to Rotary Positional Embedding
/ 4 min read
Updated:Table of Contents
What is Positional Embedding?
Let’s start with a simple sentence: “Big apple and small apple.” In this sentence, we have two “apple”. Even though they are the same word, they have different meanings. The first “apple” refers to a big apple, while the second “apple” refers to a small apple. To distinguish between these two “apple”, we need to consider their positions in the sentence.(First “apple” is close to “big”, while second “apple” is close to “small”.)
Previous approaches to positional embedding(Additive)
In the original transformer model, positional embedding is implemented as an additive method. Given a token embedding , the positional embedding is added to it:
However, this additive method has a limitation. It cannot capture the relative position between tokens effectively. Adding the positional embedding and applying self-attention wouldn’t model the relative position between tokens well.
Rotary Positional Embedding(Multiplicative)
In the paper ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING, the authors propose a new method for positional embedding called Rotary Positional Embedding. This is done by matmul the token embedding with a rotation matrix.
Terminology
: Dimension of hidden state
: Token embedding, Query, Key for th token. These are all in unless specified.
: Rotated token embeddings, Queries, Keys for th token. These are all in unless specified.
Complex Space
Representation of 2D vector in complex space
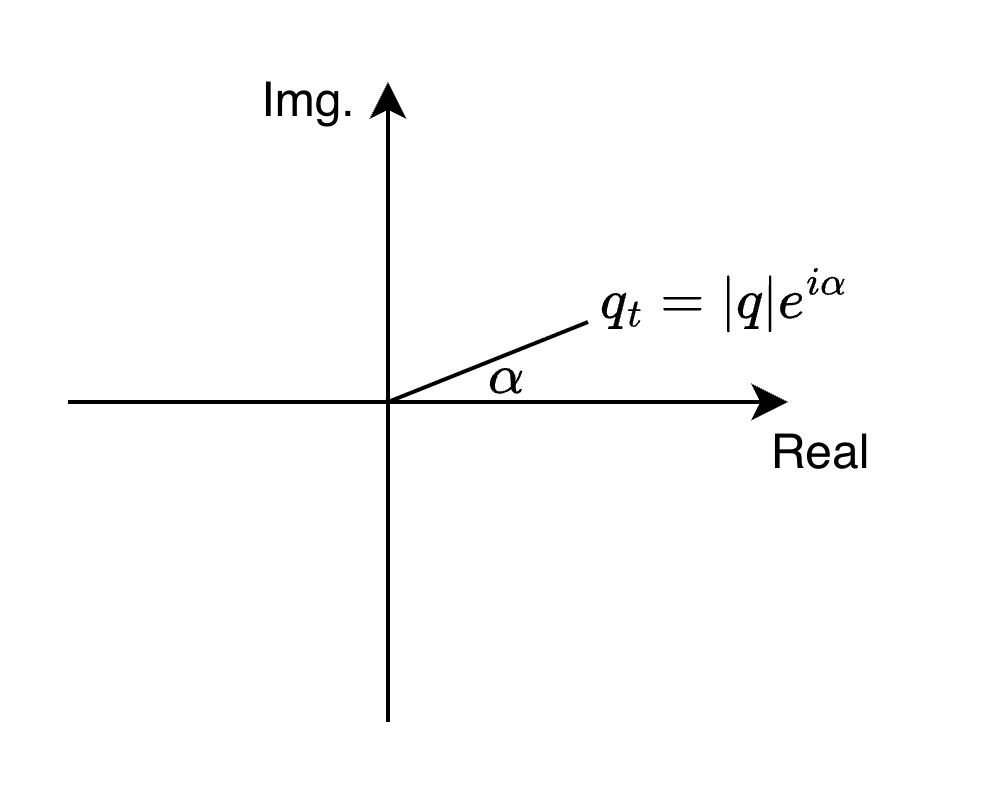
For any 2D vector , we can represent it in the complex plane as:
Where is the magnitude of the vector and is the angle it makes with the positive x-axis.
This is all due to Euler’s formula:
Rotation in complex space
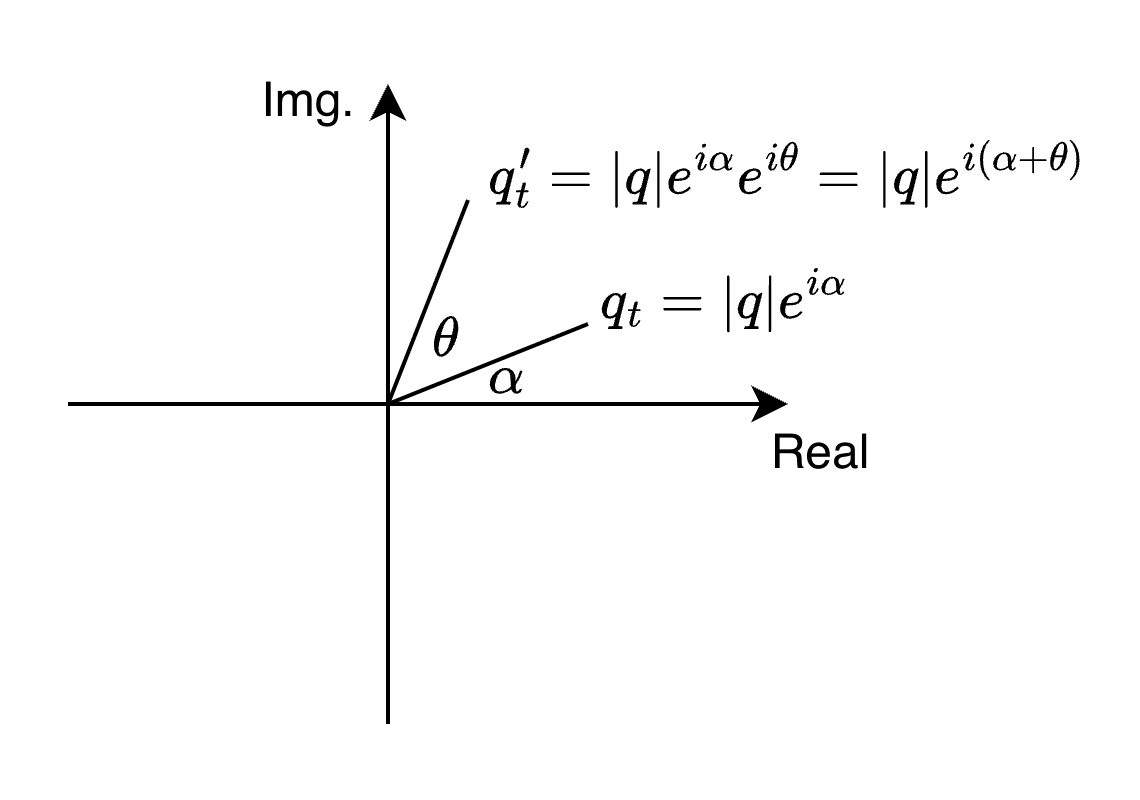
In the complex plane, we can perform a rotation by multiplying a complex number with another complex number that represents the rotation. For example, if we want to rotate a vector by an angle , we can multiply it with :
Details of Rotary Positional Embedding(with hidden_dim=2)
Let’s consider a simple case where the hidden dimension is 2. Given a token embedding at position , , the rotary positional embedding is applied as a rotation in the complex plane.
First, let’s define the token embeddings in complex plane:
The rotation is defined as follows:
rotates by and rotates by .
By doing so, if we apply inner product between and , we can capture the relative position between and :
The inner product in complex space is defined as follows:
As you can see, the inner product between and depends on the relative position between and through the term . This allows the model to capture the relative positional information effectively.
In real implementation, we don’t use the concept of complex plane. Instead, we use 2D rotation matrix to achieve the same effect. In this post, I will not go into the details of 2D rotation matrix. If you are interested, check here
Expanding the RoPE into hidden_dim=
In practice, the hidden dimension is usually much larger than 2. In this case, we can apply the same rotation to each pair of dimensions. For example, if the hidden dimension is 4, we can apply the same rotation to the first two dimensions and the last two dimensions:
Assume .
Applying rotation would be as follows:
- Rotate the first two dimensions with :
- Rotate the last two dimensions with :
You may wonder why we use different for different dimensions. This is because we want to capture the positional information at different frequency. Recall ()