Table of Contents
Summary
After “Attention is All You Need” was published in 2017, attention mechanism has been widely used in various AI models. However, the original attention mechanism has some limitations, growing size of KV caches. To overcome this issue, Deepseek-v2 introduces Multihead Latent Attention (MLA) technique, which compresses the KV caches into a smaller latent space, and also allows more efficient attention computation.
Terminology
: hidden state for th token
: Dimension of hidden state
: Key for th token
: Value for th token
: Query for th token
: Dimension of latent representation for KV cache
: Latent representation of KV cache for th token. In other words, this is compressed representation of and . This can be decompressed into and through linear transformation.
: Down projection matrix for KV cache. This matrix transforms into
: Up projection matrix for Key. This matrix transforms into .
: Up projection matrix for Value. This matrix transforms into .
: Dimension of latent representation for Query
: Latent representation of Query for th token. This is compressed representation of . This can be decompressed into through linear transformation.
: Down projection matrix for Query. This matrix transforms into
: Up projection matrix for Query. This matrix transforms into .
: Dimension of position part for Query and Key.
: Query for position part of th token
: Key for position part of th token
: Up projection matrix for Query for position part. This matrix transforms into
: Up projection matrix for Key for position part. This matrix transforms into
Naive Implementation
The following figure illustrates the naive structure of MLA:
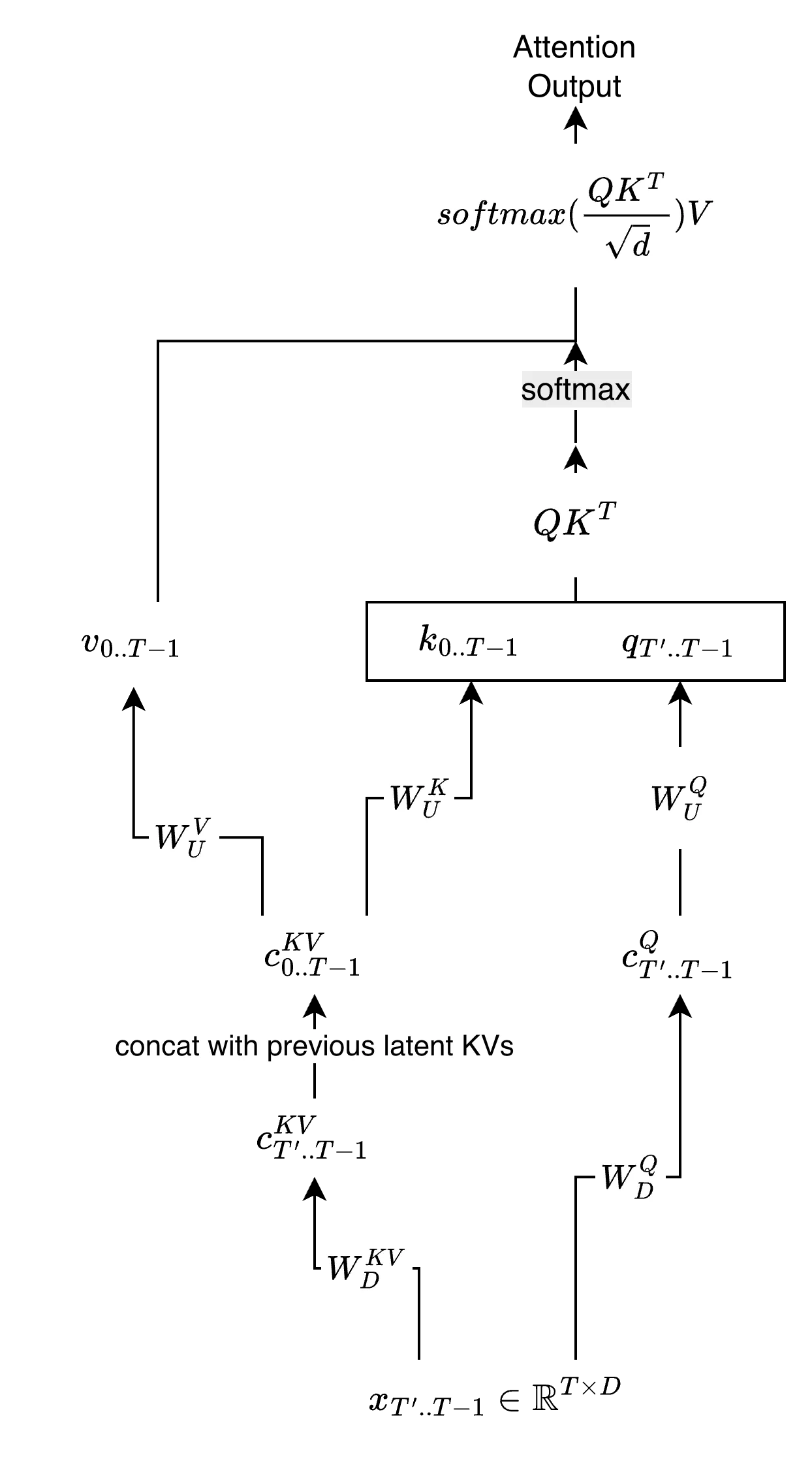
This implementation still benefits from the compression of KV cache. The memory pressure for decoding will be reduced. However, the computational cost is high because we have to up project all the latent vectors( and ) into their respective high-dimensional representations.
Optimized Implementation
Deepseek-v2 introduces a fused implementation of MLA that reduces the computational cost by fusing the up projection and attention computation. The following figure illustrates the fused structure of MLA:
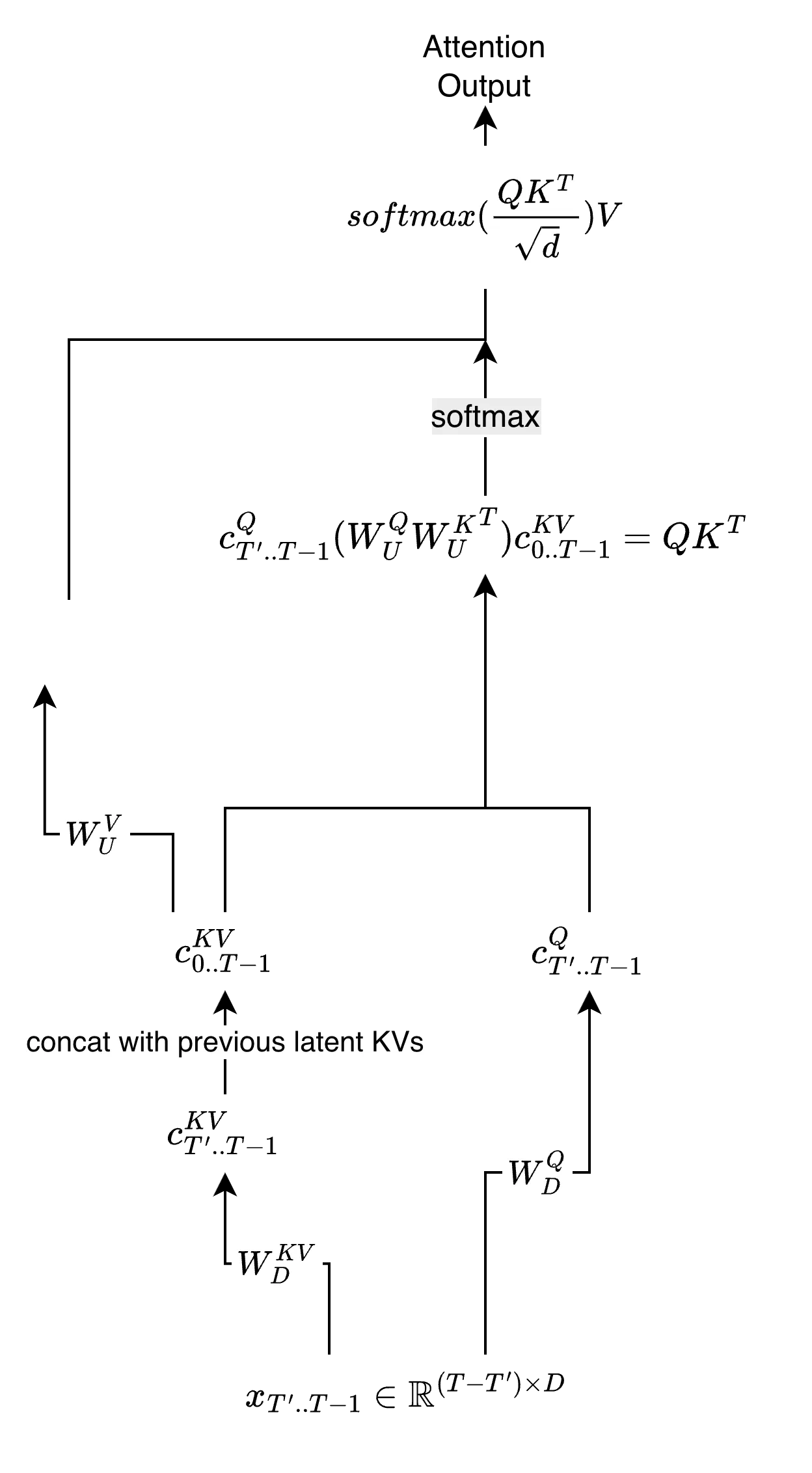
In this implementation, we calculate and store in advance.
In naive implementation, to calculate attention score(), we had to do the following steps:
- Up project into using
- Up project into using
- Calculate attention score using and
However, in the optimized implementation, we fuse the up projection and attention computation. It can be done in following steps:
- In static time, calculate and store
- Calculate attention score using and and :
Positional Embedding for MLA
Rotary positional embedding is widely used in attention. MLA also uses rotary positional embedding, but it is used quite differently to the original RoPE. In MLA, if we try to apply RoPE to and directly, we cannot utilize the fused implementation because RoPE matrix is dynamic(it changes with the position). To solve this issue, MLA separates the Query and Key into two parts: the content part and the position part.
The position part of the query and key is calculated using the rotary positional embedding:
Content part and position part are calculated in parallel, and then they are added together to get the final attention score. To make the calculation time of position part same as the content part, we decrease the dimension of the position part.()
Benefits of MLA
MLA has several benefits compared to the original attention mechanism:
- Reduced KV Cache size: By compressing the KV cache into a smaller latent space, MLA significantly reduces the memory pressure during decoding. This allows for longer sequences to be processed without running out of memory.
- Efficient Attention Computation: The fused implementation of MLA reduces the computational cost by fusing the up projection and attention computation. This allows for faster inference without sacrificing performance. Specifically, matrix is small. As a result, the required attention computation gets smaller.
- Orthogonal to GQA: MLA can be combined with GQA to further reduce the computational cost. GQA reduces the number of attention heads, while MLA reduces the dimension of KV cache. These two techniques can be used together to achieve even more efficient attention computation.