Please read Mathematical Formulation of Linear Attention first.
DeltaNet applies the delta rule to linear attention, treating the state matrix as a regression model that maps keys to values. While a naive parallel scan approach leads to prohibitive O ( L d 3 log L ) O(Ld^3\log L) O ( L d 3 log L ) O ( L C d + L d 2 ) O(LCd + Ld^2) O ( L C d + L d 2 )
q t ∈ R 1 × d q_t \in \mathbb{R}^{1 \times d} q t ∈ R 1 × d t t t k t ∈ R 1 × d k_t \in \mathbb{R}^{1 \times d} k t ∈ R 1 × d t t t v t ∈ R 1 × d v_t \in \mathbb{R}^{1 \times d} v t ∈ R 1 × d t t t o t ∈ R 1 × d o_t \in \mathbb{R}^{1 \times d} o t ∈ R 1 × d t t t Q ∈ R L × d Q \in \mathbb{R}^{L \times d} Q ∈ R L × d K ∈ R L × d K \in \mathbb{R}^{L \times d} K ∈ R L × d V ∈ R L × d V \in \mathbb{R}^{L \times d} V ∈ R L × d O ∈ R L × d O \in \mathbb{R}^{L \times d} O ∈ R L × d L L L d d d S t ∈ R d × d S_{t} \in \mathbb{R}^{d \times d} S t ∈ R d × d t t t t t t S t = ∑ i = 1 t k i T v i S_{t} = \sum_{i=1}^{t} k_i^T v_i S t = ∑ i = 1 t k i T v i G t ∈ R d × d G_t \in \mathbb{R}^{d \times d} G t ∈ R d × d t t t ⊙ \odot ⊙ I I I β t ∈ R \beta_t \in \mathbb{R} β t ∈ R
Let’s say we have the following regression model:
y = x W where y ∈ R 1 × d is the output vector W ∈ R d × d is the weight matrix x ∈ R 1 × d is the input vector \begin{aligned}
y &= xW \\
\text{where} &\quad y \in \mathbb{R}^{1 \times d} \text{ is the output vector} \\
&\quad W \in \mathbb{R}^{d \times d} \text{ is the weight matrix} \\
&\quad x \in \mathbb{R}^{1 \times d} \text{ is the input vector}
\end{aligned} y where = x W y ∈ R 1 × d is the output vector W ∈ R d × d is the weight matrix x ∈ R 1 × d is the input vector To train this model, we use the delta rule, which updates the weight matrix W W W y y y y ^ \hat{y} y ^
MSE Loss = 1 2 ∥ y ^ − y ∥ 2 = 1 2 ∥ y ^ − x W ∥ 2 \begin{aligned}
\text{MSE Loss} &= \frac{1}{2} \| \hat{y} - y \|^2 \\
&= \frac{1}{2} \| \hat{y} - xW \|^2 \\
\end{aligned} MSE Loss = 2 1 ∥ y ^ − y ∥ 2 = 2 1 ∥ y ^ − x W ∥ 2 ∂ MSE Loss ∂ W = − x T ( y ^ − x W ) = − x T y ^ + x T x W = − x T y ^ + ( x T x ) W \begin{aligned}
\frac{\partial \text{MSE Loss}}{\partial W} &= -x^T (\hat{y} - xW) \\
&= -x^T \hat{y} + x^T x W \\
&= -x^T \hat{y} + (x^T x) W
\end{aligned} ∂ W ∂ MSE Loss = − x T ( y ^ − x W ) = − x T y ^ + x T x W = − x T y ^ + ( x T x ) W W new = W old − β ∂ MSE Loss ∂ W = W old + β x T y ^ − β ( x T x ) W old = ( I − β x T x ) W old + β x T y ^ (Eq.1) \begin{aligned}
W_{\text{new}} &= W_{\text{old}} - \beta \frac{\partial \text{MSE Loss}}{\partial W} \\
&= W_{\text{old}} + \beta x^T \hat{y} - \beta (x^T x) W_{\text{old}} \\
&= (I - \beta x^T x) W_{\text{old}} + \beta x^T \hat{y}
\tag{Eq.1}
\end{aligned} W new = W old − β ∂ W ∂ MSE Loss = W old + β x T y ^ − β ( x T x ) W old = ( I − β x T x ) W old + β x T y ^ ( Eq.1 ) Let’s first recall the formulation of linear attention.
Recurrent form:
o t = ∑ j = 1 t ( q t k j T ) v j = ∑ j = 1 t q t ( k j T v j ) = q t ∑ j = 1 t k j T v j = q t S t \begin{aligned}
o_t &= \sum_{j=1}^t \left(q_tk_j^T\right)v_j \\
&= \sum_{j=1}^t q_t\left(k_j^Tv_j\right) \\
&= q_t \sum_{j=1}^t k_j^Tv_j \\
&= q_t S_t
\end{aligned} o t = j = 1 ∑ t ( q t k j T ) v j = j = 1 ∑ t q t ( k j T v j ) = q t j = 1 ∑ t k j T v j = q t S t S t S_t S t t t t t t t S t = ∑ i = 1 t k i T v i S_{t} = \sum_{i=1}^{t} k_i^T v_i S t = ∑ i = 1 t k i T v i
However, we can view the state matrix S t S_t S t
k m S t = k m ∑ i = 1 t k i T v i = ∑ i = 1 t k m k i T v i = v m + ∑ i = 1 , i ≠ m t k m k i T v i ( assuming ∥ k m ∥ = 1 ) where 1 ≤ m ≤ t k m is the key vector at m th token v m is the value vector at m th token \begin{aligned}
k_m S_t
&= k_m \sum_{i=1}^{t} k_i^T v_i \\
&= \sum_{i=1}^{t} k_m k_i^T v_i \\
&= v_m + \sum_{i=1, i \neq m}^{t} k_m k_i^T v_i \quad (\text{assuming } \|k_m\| = 1) \\
\text{where}
&\quad 1 \leq m \leq t \\
&\quad k_m \text{ is the key vector at } m \text{th token} \\
&\quad v_m \text{ is the value vector at } m \text{th token} \\
\end{aligned} k m S t where = k m i = 1 ∑ t k i T v i = i = 1 ∑ t k m k i T v i = v m + i = 1 , i = m ∑ t k m k i T v i ( assuming ∥ k m ∥ = 1 ) 1 ≤ m ≤ t k m is the key vector at m th token v m is the value vector at m th token This is the same form as the regression model we discussed in Delta Rule .
Let’s apply delta rule (Eq. 1 \text{Eq. 1} Eq. 1 Recap of Linear Attention , we are going to view the state matrix S t S_t S t
S t = ( I − β t k t T k t ) S t − 1 + β t k t T v t o t = q t S t \begin{aligned}
S_t &= (I - \beta_t k_t^T k_t) S_{t-1} + \beta_t k_t^T v_t \\
o_t &= q_t S_t
\end{aligned} S t o t = ( I − β t k t T k t ) S t − 1 + β t k t T v t = q t S t Let’s derive the parallel form of DeltaNet using parallel scan. Let’s first simplify the recurrent form of DeltaNet by defining two matrices:
M t = I − β t k t T k t X t = β t k t T v t \begin{aligned}
M_t &= I - \beta_t k_t^T k_t \\
X_t &= \beta_t k_t^T v_t \\
\end{aligned} M t X t = I − β t k t T k t = β t k t T v t Then we can rewrite the recurrent form of DeltaNet as follows:
S t = M t S t − 1 + X t o t = q t S t where S 0 = 0 \begin{aligned}
S_t &= M_t S_{t-1} + X_t \\
o_t &= q_t S_t \\
\text{where} &\quad S_0 = 0
\end{aligned} S t o t where = M t S t − 1 + X t = q t S t S 0 = 0 If we unroll the recurrence for S 0 S_0 S 0 S 1 S_1 S 1 S 2 S_2 S 2 S 3 S_3 S 3
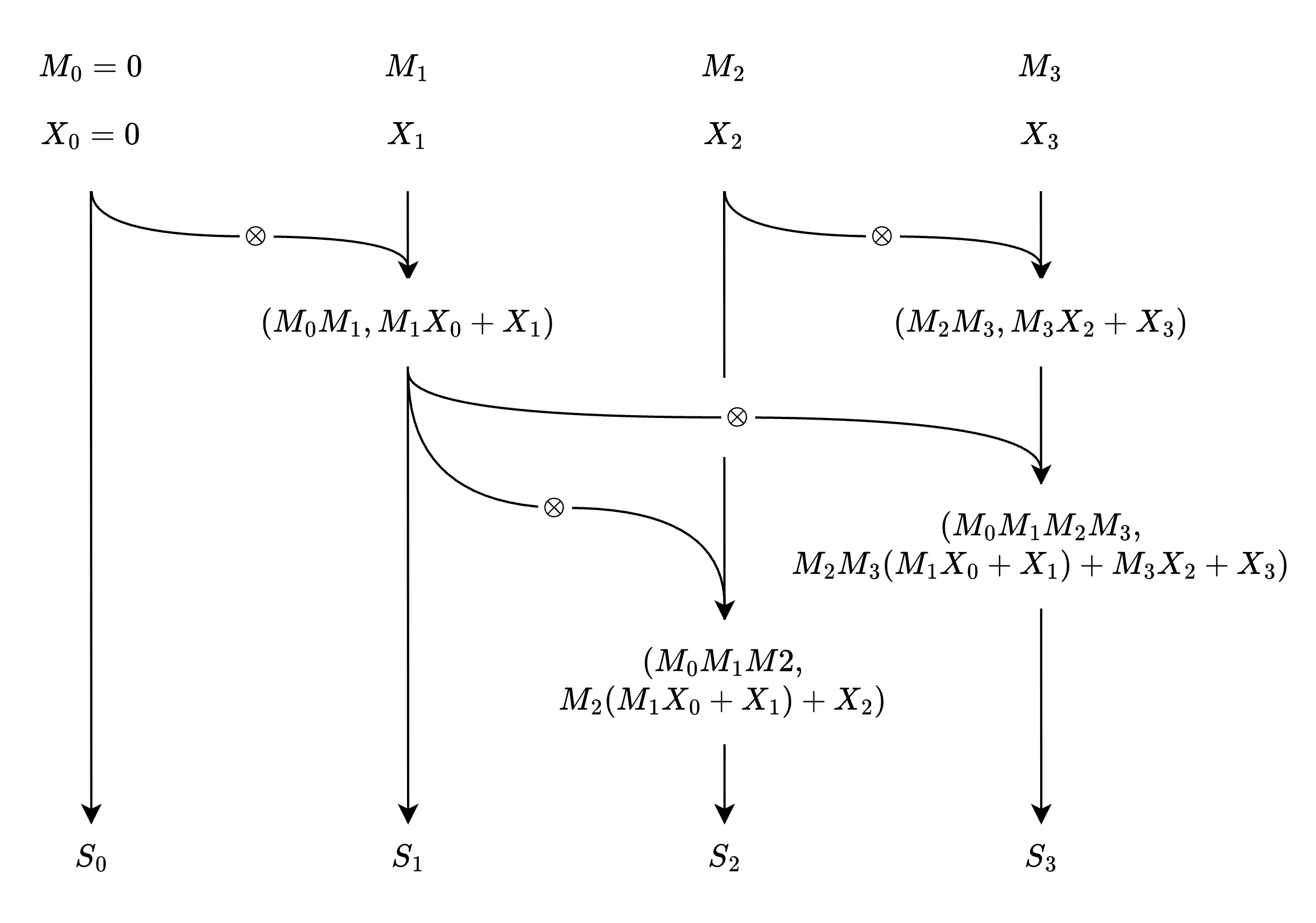
S 0 = 0 S 1 = M 1 S 0 + X 1 S 2 = M 2 S 1 + X 2 = M 2 M 1 S 0 + M 2 X 1 + X 2 S 3 = M 3 S 2 + X 3 = M 3 M 2 M 1 S 0 + M 3 M 2 X 1 + M 3 X 2 + X 3 (Eq. 2) \begin{aligned}
S_0 &= 0 \\
S_1 &= M_1 S_0 + X_1 \\
S_2 &= M_2 S_1 + X_2 = M_2 M_1 S_0 + M_2 X_1 + X_2 \\
S_3 &= M_3 S_2 + X_3 = M_3 M_2 M_1 S_0 + M_3 M_2 X_1 + M_3 X_2 + X_3 \\
\tag{Eq. 2}
\end{aligned} S 0 S 1 S 2 S 3 = 0 = M 1 S 0 + X 1 = M 2 S 1 + X 2 = M 2 M 1 S 0 + M 2 X 1 + X 2 = M 3 S 2 + X 3 = M 3 M 2 M 1 S 0 + M 3 M 2 X 1 + M 3 X 2 + X 3 ( Eq. 2 ) From ( E q .2 ) (Eq. 2) ( E q .2 ) S t S_t S t ( M t , X t ) (M_t, X_t) ( M t , X t )
( M a , X a ) ⊗ ( M b , X b ) = ( M b M a , M b X a + X b ) where M a , M b ∈ R d × d X a , X b ∈ R d × d \begin{aligned}
(M_a, X_a) \otimes (M_b, X_b) &= (M_b M_a, M_b X_a + X_b) \\
\text{where} &\quad M_a, M_b \in \mathbb{R}^{d \times d} \\
&\quad X_a, X_b \in \mathbb{R}^{d \times d}
\end{aligned} ( M a , X a ) ⊗ ( M b , X b ) where = ( M b M a , M b X a + X b ) M a , M b ∈ R d × d X a , X b ∈ R d × d The depth of the parallel scan (assume Hillis Steele scan is used) is O ( log L ) O(\log L) O ( log L ) O ( L d 3 log L ) O(L d^3\log{L}) O ( L d 3 log L ) O ( L d 2 ) O(L d^2) O ( L d 2 )
The reason why the total work is O ( L d 3 log L ) O(L d^3\log{L}) O ( L d 3 log L ) ⊗ \otimes ⊗ O ( d 3 ) O(d^3) O ( d 3 ) O ( L log L × work of operator ) = O ( L d 3 log L ) O(L \log{L} \times \text{work of operator}) = O(L d^3 \log {L}) O ( L log L × work of operator ) = O ( L d 3 log L )
The downside of parallel scan is that it requires storing all intermediate results (i.e., M 0 , M 1 , . . . , M L − 1 M_0, M_1, ..., M_{L-1} M 0 , M 1 , ... , M L − 1 X 0 , X 1 , . . . , X L − 1 X_0, X_1, ..., X_{L-1} X 0 , X 1 , ... , X L − 1
Memory Complexity = O ( L × size of intermediate result ) = O ( L × ( d 2 + d 2 ) ) = O ( L d 2 ) \begin{aligned}
\text{Memory Complexity} &= O(L \times \text{size of intermediate result}) \\
&= O(L \times (d^2 + d^2)) \\
&= O(L d^2)
\end{aligned} Memory Complexity = O ( L × size of intermediate result ) = O ( L × ( d 2 + d 2 )) = O ( L d 2 )
How can we overcome these challenges?
□ [ i ] j : = □ C i + j where □ ∈ { q , k , v , o , S , β } \Box_{[i]}^{j} := \Box_{C i + j} \\
\text{where} \quad \Box \in \{ q, k, v, o, S, \beta\} □ [ i ] j := □ C i + j where □ ∈ { q , k , v , o , S , β } △ [ i ] : = △ C i : C ( i + 1 ) where △ ∈ { Q , K , V , O } \triangle_{[i]} := \triangle_{Ci: C(i+1)} \\
\text{where} \quad \triangle \in \{ Q, K, V, O\} △ [ i ] := △ C i : C ( i + 1 ) where △ ∈ { Q , K , V , O }
Before we derive the parallel form of DeltaNet using chunking, let’s first see how chunking can be applied to linear attention.
S [ t ] r = S [ t ] 0 + ∑ j = 1 r k [ t ] j T v [ t ] j (Eq. 3) \begin{aligned}
S_{[t]}^r = S_{[t]}^{0} + \sum_{j=1}^{r} {k_{[t]}^{j}}^T v_{[t]}^{j}
\tag{Eq. 3}
\end{aligned} S [ t ] r = S [ t ] 0 + j = 1 ∑ r k [ t ] j T v [ t ] j ( Eq. 3 ) Eq. 3 \text{Eq. 3} Eq. 3 S [ t ] r S_{[t]}^r S [ t ] r S [ t ] 0 = S [ t − 1 ] C S_{[t]}^{0}=S_{[t-1]}^{C} S [ t ] 0 = S [ t − 1 ] C
o [ t ] r = q [ t ] r S [ t ] r = q [ t ] r ( S [ t ] 0 + ∑ j = 1 r k [ t ] j T v [ t ] j ) = q [ t ] r S [ t ] 0 + q [ t ] r ∑ j = 1 r k [ t ] j T v [ t ] j = q [ t ] r S [ t ] 0 + ∑ j = 1 r q [ t ] r k [ t ] j T v [ t ] j (Eq. 4) \begin{aligned}
o_{[t]}^r &= q_{[t]}^r S_{[t]}^r \\
&= q_{[t]}^r(S_{[t]}^{0} + \sum_{j=1}^{r} {k_{[t]}^{j}}^T v_{[t]}^{j}) \\
&= q_{[t]}^r S_{[t]}^{0} + q_{[t]}^r \sum_{j=1}^{r} {k_{[t]}^{j}}^T v_{[t]}^{j} \\
&= q_{[t]}^r S_{[t]}^{0} + \sum_{j=1}^{r} q_{[t]}^r {k_{[t]}^{j}}^T v_{[t]}^{j}
\tag {Eq. 4}
\end{aligned} o [ t ] r = q [ t ] r S [ t ] r = q [ t ] r ( S [ t ] 0 + j = 1 ∑ r k [ t ] j T v [ t ] j ) = q [ t ] r S [ t ] 0 + q [ t ] r j = 1 ∑ r k [ t ] j T v [ t ] j = q [ t ] r S [ t ] 0 + j = 1 ∑ r q [ t ] r k [ t ] j T v [ t ] j ( Eq. 4 ) If we convert Eq. 4 \text{Eq. 4} Eq. 4
O [ t ] = Q [ t ] S [ t ] 0 ‾ inter-chunk state passing + ( Q [ t ] K [ t ] T ⊙ Mask ) V [ t ] ‾ intra-chunk parallel computation \begin{aligned}
O_{[t]} &= \underset{\text{inter-chunk state passing}}{\underline{Q_{[t]} S_{[t]}^{0}}} + \underset{\text{intra-chunk parallel computation}}{\underline{(Q_{[t]}K_{[t]}^T \odot \text{Mask}) V_{[t]}}}
\end{aligned} O [ t ] = inter-chunk state passing Q [ t ] S [ t ] 0 + intra-chunk parallel computation ( Q [ t ] K [ t ] T ⊙ Mask ) V [ t ] Computation complexity of chunking in linear attention is O ( L C d + L d 2 ) O(LCd + Ld^2) O ( L C d + L d 2 )
The reason for this is that computation for inter-chunk state passing for a single chunk requires O ( C d 2 ) O(Cd^2) O ( C d 2 ) intra-chunk parallel computation for a single chunk requires O ( C 2 d ) O(C^2d) O ( C 2 d ) L / C L/C L / C O ( L C d + L d 2 ) O(LCd + Ld^2) O ( L C d + L d 2 )
Recall the recurrent form of DeltaNet again:
S t = ( I − β t k t T k t ) S t − 1 + β t k t T v t o t = q t S t \begin{aligned}
S_t &= (I - \beta_t k_t^T k_t) S_{t-1} + \beta_t k_t^T v_t \\
o_t &= q_t S_t
\end{aligned} S t o t = ( I − β t k t T k t ) S t − 1 + β t k t T v t = q t S t S [ t ] r = ( I − β [ t ] r k [ t ] r T k [ t ] r ) S [ t ] r − 1 + β [ t ] r k [ t ] r T v [ t ] r = ∑ j = 1 r [ ( ∏ i = j + 1 r ( I − β [ t ] i k [ t ] i T k [ t ] i ) ) ‾ forgetting gate product β [ t ] j k [ t ] j T v [ t ] j ] ‾ intra-chunk parallel computation + ( ∏ l = 1 r ( I − β [ t ] l k [ t ] l T k [ t ] l ) ) S [ t − 1 ] C ‾ inter-chunk state passing (Eq. 5) \begin{aligned}
S_{[t]}^r &= (I - \beta_{[t]}^r {k_{[t]}^r}^T k_{[t]}^r) S_{[t]}^{r-1} + \beta_{[t]}^r {k_{[t]}^r}^T v_{[t]}^r \\
&= \underset{\text{intra-chunk parallel computation}}{\underline{\sum_{j=1}^r \left[ \underset {\text{forgetting gate product}}{\underline{\left( \prod_{i=j+1}^r (I - \beta_{[t]}^i {k_{[t]}^i}^T k_{[t]}^i) \right)}}\beta_{[t]}^j {k_{[t]}^j}^T v_{[t]}^j \right]}} \\ &+ \underset{\text{inter-chunk state passing}}{\underline{\left( \prod_{l=1}^r (I - \beta_{[t]}^l {k_{[t]}^l}^T k_{[t]}^l) \right) S_{[t-1]}^C}}
\tag{Eq. 5}
\end{aligned} S [ t ] r = ( I − β [ t ] r k [ t ] r T k [ t ] r ) S [ t ] r − 1 + β [ t ] r k [ t ] r T v [ t ] r = intra-chunk parallel computation j = 1 ∑ r forgetting gate product ( i = j + 1 ∏ r ( I − β [ t ] i k [ t ] i T k [ t ] i ) ) β [ t ] j k [ t ] j T v [ t ] j + inter-chunk state passing ( l = 1 ∏ r ( I − β [ t ] l k [ t ] l T k [ t ] l ) ) S [ t − 1 ] C ( Eq. 5 ) Eq. 5 \text{Eq. 5} Eq. 5 Eq. 3 \text{Eq. 3} Eq. 3 S t S_t S t
Let’s take a deeper look at the product of the forgetting gates of all subsequent tokens:
∏ i = j + 1 r ( I − β [ t ] i k [ t ] i T k [ t ] i ) \begin{aligned}
\prod_{i=j+1}^r (I - \beta_{[t]}^i {k_{[t]}^i}^T k_{[t]}^i)
\end{aligned} i = j + 1 ∏ r ( I − β [ t ] i k [ t ] i T k [ t ] i ) For simple representation, let’s define P n P_n P n
P n = ∏ i = 1 n ( I − β i k i T k i ) = ( I − β n k n T k n ) P n − 1 \begin{aligned}
P_n &= \prod_{i=1}^n (I - \beta_i k_i^T k_i) \\
&= (I - \beta_n k_n^T k_n) P_{n-1}
\end{aligned} P n = i = 1 ∏ n ( I − β i k i T k i ) = ( I − β n k n T k n ) P n − 1 Computation complexity of getting P n for n = 1 , 2 , … L P_n \quad \text{for} n=1,2,\ldots L P n for n = 1 , 2 , … L O ( L d 3 ) O(L d^3) O ( L d 3 )
The reason for this is that we need O ( d 3 ) O(d^3) O ( d 3 ) P n P_n P n P n − 1 P_{n-1} P n − 1 P n P_n P n n = 1 , 2 , … , L n=1,2,\ldots,L n = 1 , 2 , … , L O ( L d 3 ) O(L d^3) O ( L d 3 )
Memory complexity of storing P n for n = 1 , 2 , … , L P_n \quad \text{for } n=1,2,\ldots,L P n for n = 1 , 2 , … , L O ( L d 2 ) O(L d^2) O ( L d 2 )
The WY representation is a mathematical technique that allows us to represent the product of matrices in a more compact form. Specifically, it states that the product of matrices of the form ( I − β i k i T k i ) (I - \beta_i k_i^T k_i) ( I − β i k i T k i )
∏ i = 1 t ( I − β i k i T k i ) = I − ∑ j = 1 t k j T w j where w j ∈ R 1 × d for j = 1 , 2 , … , t \begin{aligned}
\prod_{i=1}^t (I - \beta_i k_i^T k_i) &= I - \sum_{j=1}^t k_j^T w_j \\
\text{where} &\quad w_j \in \mathbb{R}^{1 \times d} \quad \text{for } j=1,2,\ldots,t
\end{aligned} i = 1 ∏ t ( I − β i k i T k i ) where = I − j = 1 ∑ t k j T w j w j ∈ R 1 × d for j = 1 , 2 , … , t This can be easily proved by mathematical induction. (Proof is omitted here, but you can find it in the Appendix B.1 of the original DeltaNet paper .)
Note that the definition of vector in my blog is row-wise (R 1 × d \mathbb{R}^{1 \times d} R 1 × d R d \mathbb{R}^d R d
If you prove it by mathematical induction, you will find that w j w_j w j β j \beta_j β j k j k_j k j
w j = β j k j − ( β j k j ∑ m = 1 j − 1 k m T w m ) \begin{aligned}
w_j &= \beta_j k_j - \left( \beta_j k_j \sum_{m=1}^{j-1} k_m^T w_m \right) \\
\end{aligned} w j = β j k j − ( β j k j m = 1 ∑ j − 1 k m T w m ) According to the WY representation, the product of the forgetting gates of all subsequent tokens can be represented as follows:
∏ i = 1 t ( I − β i k i T k i ) = I − ∑ j = 1 t k j T w j where w j ∈ R 1 × d for j = 1 , 2 , … , t \begin{aligned}
\prod_{i=1}^t (I - \beta_i k_i^T k_i) &= I - \sum_{j=1}^t k_j^T w_j \\
\text{where} &\quad w_j \in \mathbb{R}^{1 \times d} \quad \text{for } j=1,2,\ldots,t
\end{aligned} i = 1 ∏ t ( I − β i k i T k i ) where = I − j = 1 ∑ t k j T w j w j ∈ R 1 × d for j = 1 , 2 , … , t The beauty starts from here. By applying the WY representation, chunking of DeltaNet becomes the same as chunking of linear attention. Proof of this is as follows:
We want to show S t = ∑ j = 1 t k j T u j Proof. Let’s use Mathematical Induction. Base Case: t = 1 S 1 = ( I − β 1 k 1 T k 1 ) S 0 + β 1 k 1 T v 1 = β 1 k 1 T v 1 = k 1 T ( β 1 v 1 ) = k 1 T u 1 Induction Hypothesis: Assume that S t − 1 = ∑ j = 1 t − 1 k j T u j We want to show that S t = ∑ j = 1 t k j T u j S t = ( I − β t k t T k t ) S t − 1 + β t k t T v t = ( I − β t k t T k t ) ∑ j = 1 t − 1 k j T u j + β t k t T v t = ∑ j = 1 t − 1 k j T u j − β t k t T k t ∑ j = 1 t − 1 k j T u j + β t k t T v t = ∑ j = 1 t − 1 k j T u j + β t k t T ( v t − k t ∑ j = 1 t − 1 k j T u j ) = ∑ j = 1 t − 1 k j T u j + k t T ( β t v t − β t k t ∑ j = 1 t − 1 k j T u j ) ‾ u t = ∑ j = 1 t k j T u j \begin{align*}
&\text{We want to show } \quad S_t = \sum_{j=1}^t k_j^T u_j \\
&\text{Proof.} \quad \text{Let's use Mathematical Induction.} \\
&\quad \text{Base Case:} \quad t=1 \\
&\quad S_1 = (I - \beta_1 k_1^T k_1) S_0 + \beta_1 k_1^T v_1 = \beta_1 k_1^T v_1 = k_1^T \left(\beta_1 v_1\right) =k_1^T u_1 \\
&\quad \text{Induction Hypothesis:} \quad \text{Assume that } S_{t-1} = \sum_{j=1}^{t-1} k_j^T u_j \\
&\quad \text{We want to show that } S_t = \sum_{j=1}^t k_j^T u_j \\
&\quad S_t = (I - \beta_t k_t^T k_t) S_{t-1} + \beta_t k_t^T v_t \\
&\quad = (I - \beta_t k_t^T k_t)\sum_{j=1}^{t-1} k_j^T u_j + \beta_t k_t^T v_t \\
&\quad = \sum_{j=1}^{t-1} k_j^T u_j - \beta_t k_t^T k_t \sum_{j=1}^{t-1} k_j^T u_j + \beta_t k_t^T v_t \\
&\quad = \sum_{j=1}^{t-1} k_j^T u_j + \beta_t k_t^T \left( v_t - k_t \sum_{j=1}^{t-1} k_j^T u_j \right) \\
&\quad = \sum_{j=1}^{t-1} k_j^T u_j + k_t^T \underset{u_t}{\underline{\left(\beta_t v_t - \beta_t k_t \sum_{j=1}^{t-1} k_j^T u_j \right)}} \\
&\quad = \sum_{j=1}^{t} k_j^T u_j
\end{align*} We want to show S t = j = 1 ∑ t k j T u j Proof. Let’s use Mathematical Induction. Base Case: t = 1 S 1 = ( I − β 1 k 1 T k 1 ) S 0 + β 1 k 1 T v 1 = β 1 k 1 T v 1 = k 1 T ( β 1 v 1 ) = k 1 T u 1 Induction Hypothesis: Assume that S t − 1 = j = 1 ∑ t − 1 k j T u j We want to show that S t = j = 1 ∑ t k j T u j S t = ( I − β t k t T k t ) S t − 1 + β t k t T v t = ( I − β t k t T k t ) j = 1 ∑ t − 1 k j T u j + β t k t T v t = j = 1 ∑ t − 1 k j T u j − β t k t T k t j = 1 ∑ t − 1 k j T u j + β t k t T v t = j = 1 ∑ t − 1 k j T u j + β t k t T ( v t − k t j = 1 ∑ t − 1 k j T u j ) = j = 1 ∑ t − 1 k j T u j + k t T u t ( β t v t − β t k t j = 1 ∑ t − 1 k j T u j ) = j = 1 ∑ t k j T u j As a result, the computation complexity of chunking in DeltaNet with WY representation is the same as chunking in linear attention, which is O ( L C d + L d 2 ) O(LCd + Ld^2) O ( L C d + L d 2 )
Ok, we are going to simplify Eq. 5 \text{Eq. 5} Eq. 5
S [ t ] r = ( I − β [ t ] r k [ t ] r T k [ t ] r ) S [ t ] r − 1 + β [ t ] r k [ t ] r T v [ t ] r = ∑ j = 1 r [ ( ∏ i = j + 1 r ( I − β [ t ] i k [ t ] i T k [ t ] i ) ) ‾ forgetting gate product β [ t ] j k [ t ] j T v [ t ] j ] ‾ intra-chunk computation + ( ∏ l = 1 r ( I − β [ t ] l k [ t ] l T k [ t ] l ) ) S [ t − 1 ] C ‾ inter-chunk state passing = ∑ j = 1 r k [ t ] j T u [ t ] j ‾ intra-chunk computation + ( I − ∑ l = 1 r k [ t ] l T w [ t ] l ) S [ t − 1 ] C ‾ inter-chunk state passing where u [ t ] j = β [ t ] j v [ t ] j − β [ t ] j k [ t ] j ∑ m = 1 j − 1 k [ t ] m T u [ t ] m w [ t ] l = β [ t ] l k [ t ] l − β [ t ] l k [ t ] l ( ∑ m = 1 l − 1 k [ t ] m T w [ t ] m ) (Eq. 6) \begin{aligned}
S_{[t]}^r &= (I - \beta_{[t]}^r {k_{[t]}^r}^T k_{[t]}^r) S_{[t]}^{r-1} + \beta_{[t]}^r {k_{[t]}^r}^T v_{[t]}^r \\
&= \underset{\text{intra-chunk computation}}{\underline{\sum_{j=1}^r \left[ \underset {\text{forgetting gate product}}{\underline{\left( \prod_{i=j+1}^r (I - \beta_{[t]}^i {k_{[t]}^i}^T k_{[t]}^i) \right)}} \beta_{[t]}^j {k_{[t]}^j}^T v_{[t]}^j \right]}} \\ &+ \underset{\text{inter-chunk state passing}}{\underline{\left( \prod_{l=1}^r (I - \beta_{[t]}^l {k_{[t]}^l}^T k_{[t]}^l) \right) S_{[t-1]}^C}} \\
&= \underset{\text{intra-chunk computation}}{\underline{\sum_{j=1}^r {k_{[t]}^j}^T u_{[t]}^j}} + \underset{\text{inter-chunk state passing}}{\underline{\left( I - \sum_{l=1}^r {k_{[t]}^l}^T w_{[t]}^l \right) S_{[t-1]}^C}} \\
\quad \text{where} &\quad u_{[t]}^j = \beta_{[t]}^j v_{[t]}^j - \beta_{[t]}^j k_{[t]}^j \sum_{m=1}^{j-1} {k_{[t]}^m}^T u_{[t]}^m \\
&\quad w_{[t]}^l = \beta_{[t]}^l {k_{[t]}^l} - \beta_{[t]}^l {k_{[t]}^l} \left( \sum_{m=1}^{l-1} {k_{[t]}^m}^T w_{[t]}^m \right)
\tag{Eq. 6}
\end{aligned} S [ t ] r where = ( I − β [ t ] r k [ t ] r T k [ t ] r ) S [ t ] r − 1 + β [ t ] r k [ t ] r T v [ t ] r = intra-chunk computation j = 1 ∑ r forgetting gate product ( i = j + 1 ∏ r ( I − β [ t ] i k [ t ] i T k [ t ] i ) ) β [ t ] j k [ t ] j T v [ t ] j + inter-chunk state passing ( l = 1 ∏ r ( I − β [ t ] l k [ t ] l T k [ t ] l ) ) S [ t − 1 ] C = intra-chunk computation j = 1 ∑ r k [ t ] j T u [ t ] j + inter-chunk state passing ( I − l = 1 ∑ r k [ t ] l T w [ t ] l ) S [ t − 1 ] C u [ t ] j = β [ t ] j v [ t ] j − β [ t ] j k [ t ] j m = 1 ∑ j − 1 k [ t ] m T u [ t ] m w [ t ] l = β [ t ] l k [ t ] l − β [ t ] l k [ t ] l ( m = 1 ∑ l − 1 k [ t ] m T w [ t ] m ) ( Eq. 6 ) The output is computed as follows:
o [ t ] r = q [ t ] r S [ t ] r = q [ t ] r ( ∑ j = 1 r k [ t ] j T u [ t ] j + ( I − ∑ l = 1 r k [ t ] l T w [ t ] l ) S [ t − 1 ] C ) = q [ t ] r ∑ j = 1 r k [ t ] j T u [ t ] j + q [ t ] r ( I − ∑ l = 1 r k [ t ] l T w [ t ] l ) S [ t − 1 ] C = q [ t ] r ∑ j = 1 r k [ t ] j T u [ t ] j + q [ t ] r S [ t − 1 ] C − q [ t ] r ∑ l = 1 r k [ t ] l T w [ t ] l S [ t − 1 ] C = q [ t ] r S [ t − 1 ] C + ∑ j = 1 r q [ t ] r k [ t ] j T u [ t ] j − ∑ l = 1 r q [ t ] r k [ t ] l T w [ t ] l S [ t − 1 ] C = q [ t ] r S [ t − 1 ] C + ∑ j = 1 r q [ t ] r k [ t ] j T ( u [ t ] j − w [ t ] j S [ t − 1 ] C ) (Eq. 7) \begin{aligned}
o_{[t]}^r &= q_{[t]}^r S_{[t]}^r \\
&= q_{[t]}^r \left( \sum_{j=1}^r {k_{[t]}^j}^T u_{[t]}^j + \left( I - \sum_{l=1}^r {k_{[t]}^l}^T w_{[t]}^l \right) S_{[t-1]}^C \right) \\
&= q_{[t]}^r \sum_{j=1}^r {k_{[t]}^j}^T u_{[t]}^j + q_{[t]}^r \left( I - \sum_{l=1}^r {k_{[t]}^l}^T w_{[t]}^l \right) S_{[t-1]}^C \\
&= q_{[t]}^r \sum_{j=1}^r {k_{[t]}^j}^T u_{[t]}^j + q_{[t]}^r S_{[t-1]}^C - q_{[t]}^r \sum_{l=1}^r {k_{[t]}^l}^T w_{[t]}^l S_{[t-1]}^C \\
&= q_{[t]}^r S_{[t-1]}^C + \sum_{j=1}^r q_{[t]}^r {k_{[t]}^j}^T u_{[t]}^j - \sum_{l=1}^r q_{[t]}^r {k_{[t]}^l}^T w_{[t]}^l S_{[t-1]}^C \\
&= q_{[t]}^r S_{[t-1]}^C + \sum_{j=1}^r q_{[t]}^r {k_{[t]}^j}^T \left(u_{[t]}^j - w_{[t]}^j S_{[t-1]}^C \right)
\tag{Eq. 7}
\end{aligned} o [ t ] r = q [ t ] r S [ t ] r = q [ t ] r ( j = 1 ∑ r k [ t ] j T u [ t ] j + ( I − l = 1 ∑ r k [ t ] l T w [ t ] l ) S [ t − 1 ] C ) = q [ t ] r j = 1 ∑ r k [ t ] j T u [ t ] j + q [ t ] r ( I − l = 1 ∑ r k [ t ] l T w [ t ] l ) S [ t − 1 ] C = q [ t ] r j = 1 ∑ r k [ t ] j T u [ t ] j + q [ t ] r S [ t − 1 ] C − q [ t ] r l = 1 ∑ r k [ t ] l T w [ t ] l S [ t − 1 ] C = q [ t ] r S [ t − 1 ] C + j = 1 ∑ r q [ t ] r k [ t ] j T u [ t ] j − l = 1 ∑ r q [ t ] r k [ t ] l T w [ t ] l S [ t − 1 ] C = q [ t ] r S [ t − 1 ] C + j = 1 ∑ r q [ t ] r k [ t ] j T ( u [ t ] j − w [ t ] j S [ t − 1 ] C ) ( Eq. 7 ) If we expand Eq. 6 \text{Eq. 6} Eq. 6 Eq. 7 \text{Eq. 7} Eq. 7
S [ t ] 0 : C = ( I − K [ t ] T W [ t ] 0 : C ) S [ t − 1 ] C + K [ t ] 0 : C T U [ t ] 0 : C = S [ t − 1 ] C + K [ t ] 0 : C T ( U [ t ] 0 : C − W [ t ] 0 : C S [ t − 1 ] C ) ‾ Delta corrected Value O [ t ] 0 : C = Q [ t ] 0 : C S [ t − 1 ] C + ( Q [ t ] 0 : C K [ t ] 0 : C T ⊙ Mask ) ( U [ t ] 0 : C − W [ t ] 0 : C S [ t − 1 ] C ) ‾ Delta corrected Value \begin{aligned}
S_{[t]}^{0:C} &= (I - K_{[t]}^T W_{[t]}^{0:C}) S_{[t-1]}^C + {K_{[t]}^{0:C}}^T U_{[t]}^{0:C} \\
&= S_{[t-1]}^C + {K_{[t]}^{0:C}}^T \underset{\text{Delta corrected Value}}{\underline{\left(U_{[t]}^{0:C} - W_{[t]}^{0:C} S_{[t-1]}^C \right)}} \\
O_{[t]}^{0:C} &= Q_{[t]}^{0:C}S_{[t-1]}^C + (Q_{[t]}^{0:C}{K_{[t]}^{0:C}}^T \odot \text{Mask}) \underset{\text{Delta corrected Value}}{\underline{(U_{[t]}^{0:C} - W_{[t]}^{0:C} S_{[t-1]}^C)}}
\end{aligned} S [ t ] 0 : C O [ t ] 0 : C = ( I − K [ t ] T W [ t ] 0 : C ) S [ t − 1 ] C + K [ t ] 0 : C T U [ t ] 0 : C = S [ t − 1 ] C + K [ t ] 0 : C T Delta corrected Value ( U [ t ] 0 : C − W [ t ] 0 : C S [ t − 1 ] C ) = Q [ t ] 0 : C S [ t − 1 ] C + ( Q [ t ] 0 : C K [ t ] 0 : C T ⊙ Mask ) Delta corrected Value ( U [ t ] 0 : C − W [ t ] 0 : C S [ t − 1 ] C ) Recall the definition of u u u w w w
u [ t ] j = β [ t ] j v [ t ] j − β [ t ] j k [ t ] j ∑ m = 1 j − 1 k [ t ] m T u [ t ] m w [ t ] l = β [ t ] l k [ t ] l − β [ t ] l k [ t ] l ( ∑ m = 1 l − 1 k [ t ] m T w [ t ] m ) \begin{aligned}
u_{[t]}^j &= \beta_{[t]}^j v_{[t]}^j - \beta_{[t]}^j k_{[t]}^j \sum_{m=1}^{j-1} {k_{[t]}^m}^T u_{[t]}^m \\
w_{[t]}^l &= \beta_{[t]}^l {k_{[t]}^l} - \beta_{[t]}^l {k_{[t]}^l} \left( \sum_{m=1}^{l-1} {k_{[t]}^m}^T w_{[t]}^m \right)
\end{aligned} u [ t ] j w [ t ] l = β [ t ] j v [ t ] j − β [ t ] j k [ t ] j m = 1 ∑ j − 1 k [ t ] m T u [ t ] m = β [ t ] l k [ t ] l − β [ t ] l k [ t ] l ( m = 1 ∑ l − 1 k [ t ] m T w [ t ] m ) We only discussed the recurrent form of u u u w w w u u u w w w u u u w w w
w 0 = β 0 k 0 w 1 = β 1 ( k 1 − k 1 k 0 T w 0 ) = β 1 ( k 1 − a 1 , 0 β 0 k 0 ) w 2 = β 2 ( k 2 − k 2 ( k 0 T w 0 + k 1 T w 1 ) ) = β 2 ( k 2 − a 2 , 0 w 0 − a 2 , 1 w 1 ) ⋮ where a i , j = k i k j T \begin{aligned}
& w_{0} = \beta_{0} k_{0} \\
& w_{1} = \beta_{1} (k_{1} - k_{1} k_{0}^T w_0) \\
&= \beta_{1} (k_{1} - a_{1,0} \beta_0 k_0) \\
& w_{2} = \beta_{2} (k_{2} - k_{2} (k_{0}^T w_0 + k_{1}^T w_1)) \\
&= \beta_{2} (k_{2} - a_{2,0} w_0 - a_{2,1} w_1) \\
& \vdots \\
& \quad \text{where} \quad a_{i,j} = k_i k_j^T \\
\end{aligned} w 0 = β 0 k 0 w 1 = β 1 ( k 1 − k 1 k 0 T w 0 ) = β 1 ( k 1 − a 1 , 0 β 0 k 0 ) w 2 = β 2 ( k 2 − k 2 ( k 0 T w 0 + k 1 T w 1 )) = β 2 ( k 2 − a 2 , 0 w 0 − a 2 , 1 w 1 ) ⋮ where a i , j = k i k j T w 0 = β 0 k 0 β 1 a 1 , 0 w 0 + w 1 = β 1 k 1 β 2 a 2 , 0 w 0 + β 2 a 2 , 1 w 1 + w 2 = β 2 k 2 ⋮ \begin{aligned}
& w_{0} = \beta_{0} k_{0} \\
& \beta_{1} a_{1,0} w_0 + w_{1} = \beta_{1} k_{1}\\
& \beta_{2} a_{2,0} w_0 + \beta_{2} a_{2,1} w_1 + w_{2} = \beta_{2} k_{2} \\
& \vdots \\
\end{aligned} w 0 = β 0 k 0 β 1 a 1 , 0 w 0 + w 1 = β 1 k 1 β 2 a 2 , 0 w 0 + β 2 a 2 , 1 w 1 + w 2 = β 2 k 2 ⋮ [ 1 0 0 ⋯ 0 β 1 a 1 , 0 1 0 ⋯ 0 β 2 a 2 , 0 β 2 a 2 , 1 1 ⋯ 0 ⋮ ⋮ ⋮ ⋱ ⋮ β r a r , 0 β r a r , 1 β r a r , 2 ⋯ 1 ] [ w 0 w 1 w 2 ⋮ w r ] = [ β 0 k 0 β 1 k 1 β 2 k 2 ⋮ β r k r ] \begin{aligned}
\begin{bmatrix}
1 & 0 & 0 & \cdots & 0 \\
\beta_{1} a_{1,0} & 1 & 0 & \cdots & 0 \\
\beta_{2} a_{2,0} & \beta_{2} a_{2,1} & 1 & \cdots & 0 \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
\beta_{r} a_{r,0} & \beta_{r} a_{r,1} & \beta_{r} a_{r,2} & \cdots & 1 \\
\end{bmatrix}
\begin{bmatrix}
w_0 \\
w_1 \\
w_2 \\
\vdots \\
w_r \\
\end{bmatrix}
=
\begin{bmatrix}
\beta_{0} k_{0} \\
\beta_{1} k_{1} \\
\beta_{2} k_{2} \\
\vdots \\
\beta_{r} k_{r} \\
\end{bmatrix}
\end{aligned} 1 β 1 a 1 , 0 β 2 a 2 , 0 ⋮ β r a r , 0 0 1 β 2 a 2 , 1 ⋮ β r a r , 1 0 0 1 ⋮ β r a r , 2 ⋯ ⋯ ⋯ ⋱ ⋯ 0 0 0 ⋮ 1 w 0 w 1 w 2 ⋮ w r = β 0 k 0 β 1 k 1 β 2 k 2 ⋮ β r k r Let’s define matrix I − A I-A I − A
I − A = [ 1 0 0 ⋯ 0 β 1 a 1 , 0 1 0 ⋯ 0 β 2 a 2 , 0 β 2 a 2 , 1 1 ⋯ 0 ⋮ ⋮ ⋮ ⋱ ⋮ β r a r , 0 β r a r , 1 β r a r , 2 ⋯ 1 ] \begin{aligned}
I - A =
\begin{bmatrix}
1 & 0 & 0 & \cdots & 0 \\
\beta_{1} a_{1,0} & 1 & 0 & \cdots & 0 \\
\beta_{2} a_{2,0} & \beta_{2} a_{2,1} & 1 & \cdots & 0 \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
\beta_{r} a_{r,0} & \beta_{r} a_{r,1} & \beta_{r} a_{r,2} & \cdots & 1 \\
\end{bmatrix}
\end{aligned} I − A = 1 β 1 a 1 , 0 β 2 a 2 , 0 ⋮ β r a r , 0 0 1 β 2 a 2 , 1 ⋮ β r a r , 1 0 0 1 ⋮ β r a r , 2 ⋯ ⋯ ⋯ ⋱ ⋯ 0 0 0 ⋮ 1 ( I − A ) W = diag ( β ) K where W = [ w 0 w 1 w 2 ⋮ w r ] K = [ k 0 k 1 k 2 ⋮ k r ] diag ( β ) = [ β 0 0 0 ⋯ 0 0 β 1 0 ⋯ 0 0 0 β 2 ⋯ 0 ⋮ ⋮ ⋮ ⋱ ⋮ 0 0 0 ⋯ β r ] \begin{aligned}
(I-A) W = \text{diag}(\beta) K \\
\text{where}
&\quad W = \begin{bmatrix}w_0 \\
w_1 \\
w_2 \\
\vdots \\
w_r \\
\end{bmatrix} \\
&\quad K = \begin{bmatrix}k_{0} \\
k_{1} \\
k_{2} \\
\vdots \\
k_{r} \\
\end{bmatrix} \\
&\quad \text{diag}(\beta) = \begin{bmatrix}\beta_{0} & 0 & 0 & \cdots & 0 \\
0 & \beta_{1} & 0 & \cdots & 0 \\
0 & 0 & \beta_{2} & \cdots & 0 \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
0 & 0 & 0 & \cdots & \beta_{r} \\
\end{bmatrix}
\end{aligned} ( I − A ) W = diag ( β ) K where W = w 0 w 1 w 2 ⋮ w r K = k 0 k 1 k 2 ⋮ k r diag ( β ) = β 0 0 0 ⋮ 0 0 β 1 0 ⋮ 0 0 0 β 2 ⋮ 0 ⋯ ⋯ ⋯ ⋱ ⋯ 0 0 0 ⋮ β r W = ( I − A ) − 1 diag ( β ) K \begin{aligned}
W &= (I - A)^{-1} \text{diag}(\beta)K
\end{aligned} W = ( I − A ) − 1 diag ( β ) K We have a powerful property of I − A I-A I − A I − A I-A I − A
As a result, inverse of I − A I-A I − A
( I − A ) − 1 = I + A + A 2 + A 3 + ⋯ + A C where C is the chunk size \begin{aligned}
(I-A)^{-1} &= I + A + A^2 + A^3 + \cdots + A^C \\
\text{where} &\quad C \text{ is the chunk size}
\end{aligned} ( I − A ) − 1 where = I + A + A 2 + A 3 + ⋯ + A C C is the chunk size W [ t ] 0 : C = ( I − A [ t ] 0 : C ) − 1 diag ( β [ t ] 0 : C ) K [ t ] 0 : C U [ t ] 0 : C = ( I − A [ t ] 0 : C ) − 1 diag ( β [ t ] 0 : C ) V [ t ] 0 : C \begin{aligned}
W_{[t]}^{0:C} &= (I - A_{[t]}^{0:C})^{-1} \text{diag}(\beta_{[t]}^{0:C})K_{[t]}^{0:C} \\
U_{[t]}^{0:C} &= (I - A_{[t]}^{0:C})^{-1} \text{diag}(\beta_{[t]}^{0:C})V_{[t]}^{0:C} \\
\end{aligned} W [ t ] 0 : C U [ t ] 0 : C = ( I − A [ t ] 0 : C ) − 1 diag ( β [ t ] 0 : C ) K [ t ] 0 : C = ( I − A [ t ] 0 : C ) − 1 diag ( β [ t ] 0 : C ) V [ t ] 0 : C Form is somewhat same as pure linear attention!
Preparing auxiliary matrices A [ t ] 0 : C = tril ( diag ( β [ t ] 0 : C ) K [ t ] 0 : C K [ t ] 0 : C T , − 1 ) W [ t ] 0 : C = ( I − A [ t ] 0 : C ) − 1 diag ( β [ t ] 0 : C ) K [ t ] 0 : C U [ t ] 0 : C = ( I − A [ t ] 0 : C ) − 1 diag ( β [ t ] 0 : C ) V [ t ] 0 : C Main computation S [ t ] 0 : C = ( I − K [ t ] T W [ t ] 0 : C ) S [ t − 1 ] C + K [ t ] 0 : C T U [ t ] 0 : C = S [ t − 1 ] C + K [ t ] 0 : C T ( U [ t ] 0 : C − W [ t ] 0 : C S [ t − 1 ] C ) ‾ Delta corrected Value O [ t ] 0 : C = Q [ t ] 0 : C S [ t − 1 ] C + ( Q [ t ] 0 : C K [ t ] 0 : C T ⊙ Mask ) ( U [ t ] 0 : C − W [ t ] 0 : C S [ t − 1 ] C ) ‾ Delta corrected Value \begin{aligned}
&\text{Preparing auxiliary matrices} \\
A_{[t]}^{0:C} &= \text{tril}(\text{diag}(\beta_{[t]}^{0:C})K_{[t]}^{0:C} {K_{[t]}^{0:C}}^T, -1)\\
W_{[t]}^{0:C} &= (I - A_{[t]}^{0:C})^{-1} \text{diag}(\beta_{[t]}^{0:C})K_{[t]}^{0:C} \\
U_{[t]}^{0:C} &= (I - A_{[t]}^{0:C})^{-1} \text{diag}(\beta_{[t]}^{0:C})V_{[t]}^{0:C} \\ \\
&\text{Main computation} \\
S_{[t]}^{0:C} &= (I - K_{[t]}^T W_{[t]}^{0:C}) S_{[t-1]}^C + {K_{[t]}^{0:C}}^T U_{[t]}^{0:C} \\
&= S_{[t-1]}^C + {K_{[t]}^{0:C}}^T \underset{\text{Delta corrected Value}}{\underline{\left(U_{[t]}^{0:C} - W_{[t]}^{0:C} S_{[t-1]}^C \right)}} \\
O_{[t]}^{0:C} &= Q_{[t]}^{0:C}S_{[t-1]}^C + (Q_{[t]}^{0:C}{K_{[t]}^{0:C}}^T \odot \text{Mask}) \underset{\text{Delta corrected Value}}{\underline{(U_{[t]}^{0:C} - W_{[t]}^{0:C} S_{[t-1]}^C)}} \\
\end{aligned} A [ t ] 0 : C W [ t ] 0 : C U [ t ] 0 : C S [ t ] 0 : C O [ t ] 0 : C Preparing auxiliary matrices = tril ( diag ( β [ t ] 0 : C ) K [ t ] 0 : C K [ t ] 0 : C T , − 1 ) = ( I − A [ t ] 0 : C ) − 1 diag ( β [ t ] 0 : C ) K [ t ] 0 : C = ( I − A [ t ] 0 : C ) − 1 diag ( β [ t ] 0 : C ) V [ t ] 0 : C Main computation = ( I − K [ t ] T W [ t ] 0 : C ) S [ t − 1 ] C + K [ t ] 0 : C T U [ t ] 0 : C = S [ t − 1 ] C + K [ t ] 0 : C T Delta corrected Value ( U [ t ] 0 : C − W [ t ] 0 : C S [ t − 1 ] C ) = Q [ t ] 0 : C S [ t − 1 ] C + ( Q [ t ] 0 : C K [ t ] 0 : C T ⊙ Mask ) Delta corrected Value ( U [ t ] 0 : C − W [ t ] 0 : C S [ t − 1 ] C ) We’ve gone through the mathematical formulation of DeltaNet, and derived the parallel form of DeltaNet using chunking and WY representation.